Remote Ready Biology Learning Activities has 50 remote-ready activities, which work for either your classroom or remote teaching.
A digital ecosystem, fueled by serendipity.
Serendip is an independent site partnering with faculty at multiple colleges and universities around the world. Happy exploring!
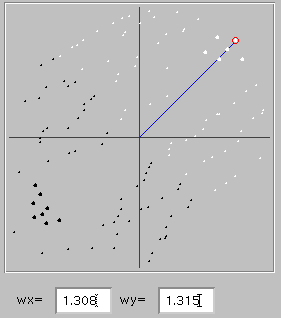 An interesting and important property of our simple network is that it generalizes: the network doesn't simply learn what names to give to things which it has experienced (the values we gave it with the black and white dots) but rather generates a classification rule which can be applied to other things as well. The figure to the left illustrates this. The network learned to discriminate a cluster of six elephants (larger white dots to upper right) from eight rabbits (eight larger black dots to lower left). The smaller white and black dots also visible in the figure were generated by clicking with the shift key depressed (you can do this with your own trained networks in the active program), and show the classifications for these points which the network did not experience during training. The rule which the network developed subdivides all possible points into two regions separated by a line running from upper left to lower right, with elephants above and rabbits below that line. The line is perpendicular to the blue line which gives a graphic representation of the synaptic weights (also shown at the bottom of the figure); the x and y coordinates of the end of the blue line correspond to the synaptic weight values of the two input units. The relation between this line and the line separating the two classification regions gives valuable clues about how the network achieves a good classification, and you might want to study this relation in various networks you train to see if it helps you to better understand how the network works. For the moment, though, let's just remember that the blue line shows the weights which the network has developed to achieve the categorization.
An interesting and important property of our simple network is that it generalizes: the network doesn't simply learn what names to give to things which it has experienced (the values we gave it with the black and white dots) but rather generates a classification rule which can be applied to other things as well. The figure to the left illustrates this. The network learned to discriminate a cluster of six elephants (larger white dots to upper right) from eight rabbits (eight larger black dots to lower left). The smaller white and black dots also visible in the figure were generated by clicking with the shift key depressed (you can do this with your own trained networks in the active program), and show the classifications for these points which the network did not experience during training. The rule which the network developed subdivides all possible points into two regions separated by a line running from upper left to lower right, with elephants above and rabbits below that line. The line is perpendicular to the blue line which gives a graphic representation of the synaptic weights (also shown at the bottom of the figure); the x and y coordinates of the end of the blue line correspond to the synaptic weight values of the two input units. The relation between this line and the line separating the two classification regions gives valuable clues about how the network achieves a good classification, and you might want to study this relation in various networks you train to see if it helps you to better understand how the network works. For the moment, though, let's just remember that the blue line shows the weights which the network has developed to achieve the categorization.
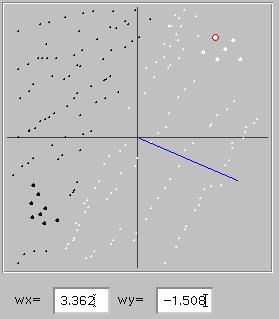 So, the network not only learns to name things which it was supposed to learn to name, but has acquired a categorizing scheme which it can use to name additional things. And now we come to our next question: where did that categorizing scheme come from? was it provided by the teacher? was it inherent in the experiences the network had ("external reality")? or was it in some sense made up by the network in a way that might be different for a different network? The answer is illustrated to the right. The network in this case consists of the same four elements as always, and was trained using exactly the same learning rule and exactly the same six elephants and eight rabbits. But, as you can see from the blue line, it clearly came up with a different categorizing scheme. Everything in the lower right quadrant, for example, was classified as an elephant, while half that quadrant was classified as a rabbit the first time around. What was different in the two cases? Only the synaptic weights that the network had before it began learning. Clearly the categorizing scheme is not inherent in either the experiences the network has during learning nor in the procedures of the learning process itself. Different starting points (which might be different for any of a wide array of reasons) also influence the categorization scheme which emerges during learning. You can (and should) verify this for yourself using the active program. Clicking on the "Set random weights" button will reset the weights without changing your training points so you can easily look to see whether you do or don't get the same solution from different starting points.
So, the network not only learns to name things which it was supposed to learn to name, but has acquired a categorizing scheme which it can use to name additional things. And now we come to our next question: where did that categorizing scheme come from? was it provided by the teacher? was it inherent in the experiences the network had ("external reality")? or was it in some sense made up by the network in a way that might be different for a different network? The answer is illustrated to the right. The network in this case consists of the same four elements as always, and was trained using exactly the same learning rule and exactly the same six elephants and eight rabbits. But, as you can see from the blue line, it clearly came up with a different categorizing scheme. Everything in the lower right quadrant, for example, was classified as an elephant, while half that quadrant was classified as a rabbit the first time around. What was different in the two cases? Only the synaptic weights that the network had before it began learning. Clearly the categorizing scheme is not inherent in either the experiences the network has during learning nor in the procedures of the learning process itself. Different starting points (which might be different for any of a wide array of reasons) also influence the categorization scheme which emerges during learning. You can (and should) verify this for yourself using the active program. Clicking on the "Set random weights" button will reset the weights without changing your training points so you can easily look to see whether you do or don't get the same solution from different starting points.
Very interesting. Is there anything the network can't do?.
Can I go back to the beginning, please?
| Forum
| Complexity | Serendip Home |