Remote Ready Biology Learning Activities has 50 remote-ready activities, which work for either your classroom or remote teaching.
A digital ecosystem, fueled by serendipity.
Serendip is an independent site partnering with faculty at multiple colleges and universities around the world. Happy exploring!
Simple things interacting in simple ways can yield surprisingly complex and elegant outcomes. But can they learn? create categories by themselves? bring order into what previously lacked order? Those are interesting questions, from lots of points of view. Computers consist of relatively simple things interacting in relatively simple ways and, it is sometimes said, computers can only do what they are told to do. Are they really that uninteresting? Could they perhaps learn? create categories? make their own order? And what about brains? Brains too consist of relatively simple things interacting in relatively simple ways. And use categories. Can one imagine how they could learn, create categories, create order? Is it possible that categories and order are actually a construction of brains, instead of something fixed and eternal which brains discover? If so, maybe categories might be made differently by different brains ... and maybe differently by computers and other even simpler systems so long as they satisfy some minimal requirement of kinds of interacting parts?
Let's see if we can come up with something simple that can learn to tell the difference between ... oh, let's see ... something simple ... how about an elephant and a rabbit?
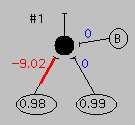
 We'll start with a simple brain (or a simple computer) which consists of four simple elements connected as shown to the left. The bottom two ovals we'll call "input" units and the filled circle we'll call an "output" unit. They are actually all we really need (for present purposes), but things will work a little better if we have a fourth "bias" element, the circle with the B in it. The input elements collect information from the outside world and send it to the output element which uses it (and information from the bias unit) to determine what it says (hopefully something useful) about the outside world.
We'll start with a simple brain (or a simple computer) which consists of four simple elements connected as shown to the left. The bottom two ovals we'll call "input" units and the filled circle we'll call an "output" unit. They are actually all we really need (for present purposes), but things will work a little better if we have a fourth "bias" element, the circle with the B in it. The input elements collect information from the outside world and send it to the output element which uses it (and information from the bias unit) to determine what it says (hopefully something useful) about the outside world.
 Let's further imagine that all elements represent information in turns of a level of activity, a number which can have any value between -1 and 1 (except for the bias unit, which always has a value of 1). A value of 1 in the left input element, for example, might indicate very tall, and a value of -1, might indicate very short (with intermediate numbers corresponding to intermediate heights). Similarly, a value of 1 in the right input element could represent very wide, and a value of -1 something much thinner (with intermediate numbers corresponding to intermediate widths). So an elephant would cause a value of (more or less) 1 in the left input element and a value of (more or less) 1 in the right input element as well (as shown in the picture to the right). A rabbit, on the other hand, would cause values of -1 in both elements.
Let's further imagine that all elements represent information in turns of a level of activity, a number which can have any value between -1 and 1 (except for the bias unit, which always has a value of 1). A value of 1 in the left input element, for example, might indicate very tall, and a value of -1, might indicate very short (with intermediate numbers corresponding to intermediate heights). Similarly, a value of 1 in the right input element could represent very wide, and a value of -1 something much thinner (with intermediate numbers corresponding to intermediate widths). So an elephant would cause a value of (more or less) 1 in the left input element and a value of (more or less) 1 in the right input element as well (as shown in the picture to the right). A rabbit, on the other hand, would cause values of -1 in both elements.
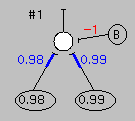
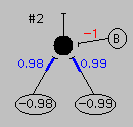 Now we need to know how numbers in the input (and bias) elements influence numbers in the output element, and we need to know what those in turn mean. Let's have the output element listen to both input elements (as well as the bias unit), but pay attention to them by some amount which can be different for each. This is a lot like one neuron in a brain receiving signals from other neurons across different synapses which have different effectivenesses, and so we'll use the term "synaptic weight" to express how much attention the output neuron pays to each input neuron (as well as to the bias neuron). This gives us three more numbers (the colored ones in the figure to the left, as well as those above), which can also be either positive or negative. If we now take each activity level, multiply it by the appropriate synaptic weight, and add them up, we get an activity level for the output element. One final step. We'll use an "activation function" to get from the activity level to the actual output: if the activity level is greater than or equal to zero, we'll make the output 1 (white in the figures). If it is less than zero, we'll make the output -1 (black in the figures). And, last of all, we'll agree that 1 means an elephant, while -1 means a rabbit.
Now we need to know how numbers in the input (and bias) elements influence numbers in the output element, and we need to know what those in turn mean. Let's have the output element listen to both input elements (as well as the bias unit), but pay attention to them by some amount which can be different for each. This is a lot like one neuron in a brain receiving signals from other neurons across different synapses which have different effectivenesses, and so we'll use the term "synaptic weight" to express how much attention the output neuron pays to each input neuron (as well as to the bias neuron). This gives us three more numbers (the colored ones in the figure to the left, as well as those above), which can also be either positive or negative. If we now take each activity level, multiply it by the appropriate synaptic weight, and add them up, we get an activity level for the output element. One final step. We'll use an "activation function" to get from the activity level to the actual output: if the activity level is greater than or equal to zero, we'll make the output 1 (white in the figures). If it is less than zero, we'll make the output -1 (black in the figures). And, last of all, we'll agree that 1 means an elephant, while -1 means a rabbit.
 There exist interconnected sets of elements which will correctly identify both elephants (right above) and rabbits (left above). And it is the particular set of synaptic weights present in such networks which gives the network this ability. With different weights, elephants would be identified as rabbits (as shown to left), and vice versa. The obvious question then is how do the weights get to their needed values? Does someone have to set them correctly, or can a network find them itself?
There exist interconnected sets of elements which will correctly identify both elephants (right above) and rabbits (left above). And it is the particular set of synaptic weights present in such networks which gives the network this ability. With different weights, elephants would be identified as rabbits (as shown to left), and vice versa. The obvious question then is how do the weights get to their needed values? Does someone have to set them correctly, or can a network find them itself?
Our simple network will distinguish elephants and rabbits, if we give it an appropriate set of synaptic weights. Is there some way to arrange things so that a simple network could discover or evolve such a set of weights itself? The answer is yes, if we add three ingredients: modifiable synaptic weights, a learning rule, and a teacher. The role of the teacher is to present input patterns, observe the resulting outputs, and, if they're wrong, to tell the network what the output should have been for that input pattern. Notice that the teacher doesn't tell the network HOW to get the right output (what the synaptic weights should be), it just tells the network what the right output should have been. Its a little bit like someone correcting pronunciation by giving the correct pronunication (without saying why or how to do that). Using that information, and a learning rule, its up to the network to figure out what adjustments to make to its synaptic weights. And the learning rule doesn't say what to do to get the right weights in any particular case either. Its a general learning rule, one which will work the same way for lots of different situations (not just elephants and rabbits).
All that the learning rule says is if you've gotten the wrong answer in some particular case, change each synaptic weight by a small amount in a direction which would make your answer closer to the right answer in that case. If an input of 1 and 1 caused an output of -1, for example, the learning rule says to decrease the strength of each synapse by a small amount (for a more formal description of the underlying algorithm go here). The idea is that with repeated small modifications of this kind, the network will end up with the appropriate set of synaptic weights to distinguish rabbits and elephants (or the different appropriate set of synaptic weights to distinguish between other things it is shown and supposed to learn). Do you think it will work? Here's the answer:
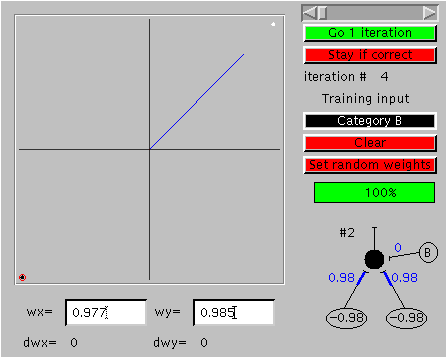
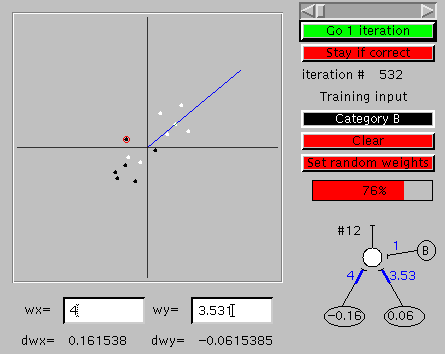
| A network which correctly identifies an elephant as an elephant and a rabbit as a rabbit is shown in the lower right of each of two illustrations of the interface of a program which implements the learning process described above. The program was started with synaptic weights that did not correctly classify both elephants and rabbits and run until it yielded the results shown. You can bring up an active version of the program elsewhere on your monitor by clicking here. The large window to the left allows one to enter the things to be distinguished (the "training input"). The rabbit is represented by the small black dot in the lower left corner, created by clicking at this location when the top "training input" control bar was black ("Category B"). Clicking on this bar itself changes the bar to white ("Category A"), and then clicking in the upper right hand corner gave the white dot corresponding to the elephant. A click on the "Go" button causes the program to select one of the things to be learned (the elephant in one of the two illustrations, the rabbit in the other), apply those values to the input elements, calculate the output value, compare it to the correct value, and make appropriate small changes to the synaptic weights (the current weights and the calculated changes in weights are shown below the large window). This process is repeated each time the "Go" button is clicked, and leads eventually to appropriate synaptic weights which no longer change. |
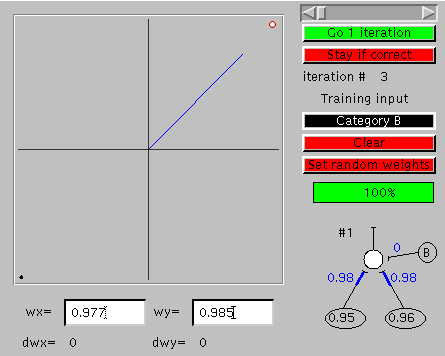
|
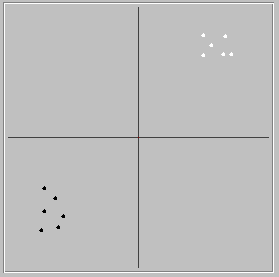 Try it yourself, using the active version of the program. You can, of course, decide you want to teach your network to discriminate tall, thin things (flagpoles?) from short, wide things (fire hydrants?) by changing where you put the white and black dots. You might also want to position the dots to see if the network can learn to distinguish between very tall/very wide and pretty tall/pretty wide (as opposed to very short/thin). And you might want to be more realistic. After all, not all elephants are the same size, nor are all rabbits. What happens if you give the network several different points for both elephants and rabbits, as in the figure to the right?
Try it yourself, using the active version of the program. You can, of course, decide you want to teach your network to discriminate tall, thin things (flagpoles?) from short, wide things (fire hydrants?) by changing where you put the white and black dots. You might also want to position the dots to see if the network can learn to distinguish between very tall/very wide and pretty tall/pretty wide (as opposed to very short/thin). And you might want to be more realistic. After all, not all elephants are the same size, nor are all rabbits. What happens if you give the network several different points for both elephants and rabbits, as in the figure to the right?
If you're persuaded that this simple set of things obeying simple rules is in fact capable of learning, lots of different things, let's go on to the question of whether it creates categories, or just learns ones that already exist elsewhere (ones you made, for example).
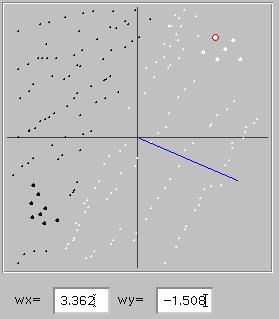
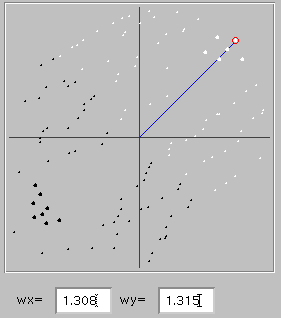 An interesting and important property of our simple network is that it generalizes: the network doesn't simply learn what names to give to things which it has experienced (the values we gave it with the black and white dots) but rather generates a classification rule which can be applied to other things as well. The figure to the left illustrates this. The network learned to discriminate a cluster of six elephants (larger white dots to upper right) from eight rabbits (eight larger black dots to lower left). The smaller white and black dots were generated by clicking with the shift key depressed (you can do this with your own trained networks in the active program), and show the classifications for these values which the network did not experience during training. The rule which the network developed subdivides all possible points into two regions separated by a line running from upper left to lower right, with elephants above and rabbits below that line. The line is perpendicular to the blue line which gives a graphic representation of the synaptic weights (also shown below); the x and y coordinates of the end of the blue line correspond to the synaptic weight values of the two input units. The relation between this line and the line separating the two classification regions gives valuable clues about how the network achieves a good classification, and you might want to study this relation in various networks you train to see if it helps you to better understand how the network works. For the moment, though, let's just remember that the blue line shows the weights which the network has developed to achieve the categorization.
An interesting and important property of our simple network is that it generalizes: the network doesn't simply learn what names to give to things which it has experienced (the values we gave it with the black and white dots) but rather generates a classification rule which can be applied to other things as well. The figure to the left illustrates this. The network learned to discriminate a cluster of six elephants (larger white dots to upper right) from eight rabbits (eight larger black dots to lower left). The smaller white and black dots were generated by clicking with the shift key depressed (you can do this with your own trained networks in the active program), and show the classifications for these values which the network did not experience during training. The rule which the network developed subdivides all possible points into two regions separated by a line running from upper left to lower right, with elephants above and rabbits below that line. The line is perpendicular to the blue line which gives a graphic representation of the synaptic weights (also shown below); the x and y coordinates of the end of the blue line correspond to the synaptic weight values of the two input units. The relation between this line and the line separating the two classification regions gives valuable clues about how the network achieves a good classification, and you might want to study this relation in various networks you train to see if it helps you to better understand how the network works. For the moment, though, let's just remember that the blue line shows the weights which the network has developed to achieve the categorization.
 So, the network not only learns to name things which it was supposed to learn to name, but has acquired a categorizing scheme which it can use to name additional things. And now we come to our next question: where did that categorizing scheme come from? was it provided by the teacher? was it inherent in the experiences the network had ("external reality")? or was it in some sense made up by the network in a way that might be different for a different network? The answer is illustrated to the right. The network in this case consists of the same four elements as always, and was trained using exactly the same learning rule and exactly the same six elephants and eight rabbits. But, as you can see from the blue line, it clearly came up with a different categorizing scheme. Everything in the lower right quadrant, for example, was classified as an elephant, while half that quadrant was classified as a rabbit the first time around. What was different in the two cases? Only the synaptic weights that the network had before it began learning. Clearly the categorizing scheme is not inherent in either the experiences the network has during learning nor in the procedures of the learning process itself. Different starting points (which might be different for any of a wide array of reasons) also influence the categorization scheme which emerges during learning.
So, the network not only learns to name things which it was supposed to learn to name, but has acquired a categorizing scheme which it can use to name additional things. And now we come to our next question: where did that categorizing scheme come from? was it provided by the teacher? was it inherent in the experiences the network had ("external reality")? or was it in some sense made up by the network in a way that might be different for a different network? The answer is illustrated to the right. The network in this case consists of the same four elements as always, and was trained using exactly the same learning rule and exactly the same six elephants and eight rabbits. But, as you can see from the blue line, it clearly came up with a different categorizing scheme. Everything in the lower right quadrant, for example, was classified as an elephant, while half that quadrant was classified as a rabbit the first time around. What was different in the two cases? Only the synaptic weights that the network had before it began learning. Clearly the categorizing scheme is not inherent in either the experiences the network has during learning nor in the procedures of the learning process itself. Different starting points (which might be different for any of a wide array of reasons) also influence the categorization scheme which emerges during learning.
Our simple network has some pretty impressive capabilities, being able not only to learn to tell the difference between elephants and rabbits but to come up with a variety of ways to summarize a given set of experiences (to categorize) where we might have thought there was only one. An obvious question, at this point, is how good IS our simple network? Are there things that more elaborate systems can learn that it can't? Are there things that we can learn that it can't?
 The answer to both those questions is yes (and so the answer to the title question is no). An example in terms of rabbits and elephants is shown to the left. Notice that we are still showing the network one set of things and telling it they are elephants and another set of things and telling it they are elephants, just like before. And the network is having the experiences and adjusting its weights accordingly, just like before. But after 500 trials, the network still isn't correctly identifying all of the examples we are showing it ... and if you try something similar yourself you'll find that, no matter how many trials you give it, the network never finds a set of weights that correctly identifies all the examples. The weights (and the categories they define) just keep changing, always with some examples incorrectly classified.
The answer to both those questions is yes (and so the answer to the title question is no). An example in terms of rabbits and elephants is shown to the left. Notice that we are still showing the network one set of things and telling it they are elephants and another set of things and telling it they are elephants, just like before. And the network is having the experiences and adjusting its weights accordingly, just like before. But after 500 trials, the network still isn't correctly identifying all of the examples we are showing it ... and if you try something similar yourself you'll find that, no matter how many trials you give it, the network never finds a set of weights that correctly identifies all the examples. The weights (and the categories they define) just keep changing, always with some examples incorrectly classified.
So, there are some problems our network will try to solve, but never get quite right. Why's that? What's the difference between things it can get right (in one or another way)? Is it that we're talking about fairly short, thin elephants and fairly tail, fat rabbits? Or is that some elephants are actually shorter and thinner than some rabbits? You can do some experiments yourself, using the active simulator, to find out (click here if you don't have the simulator available from having clicked above). The answer is closely related to the observation we made earlier about how the simulator works by creating a line which divides all possible values into two categories.
We started by wondering whether simple things interacting in simple ways could learn. And the answer is yes. So its certainly not true that computers can do only what they are told to do. Or, at least, its not true that one has to tell them explicity what to do for every example of what you want. You can give them a general set of operating instructions, and a few specific examples, and the computer will not only learn the specific examples but use these to itself create a rule, a categorizing scheme, that it can apply to additional cases.
What's particularly interesting is that the rule the computer creates may or may not be the one you had in mind. You might have had in mind that the shorter and thinner something gets, the more it should be called a rabbit (like one scheme the computer came up with), but the examples experienced are, for the computer, equally consistent with most things, even quite short and thin things, being elephants. This may seem silly, but it actually says something quite important about how many different solutions there are to particular problems, about the extent to which experience can account for observed generalizations, and probably about brains and people as well.
So:
Is it a good thing or a bad thing that different individuals may learn different things from the same set of experiences? That depends, of course, on one's perspective. If one wants uniformity out of an educational process, its not so good, in which case one ought to try to make not only the learning experiences for everyone but also the starting conditions for as similar as possible. An alternate perspective is that there are lots of somewhat different ways to do the same task, and people who learn to do it differently from one another can as a consequence subsequently learn additional things from each other (as they might learn from elephants or rabbits or computers).
That learning depends not only on particular experiences but also on pre-existing structure has some significant broader implications as well. In the sense in which it is used here, learning, with its accompanying creation of somewhat arbitrary categories, is not, of course, something which occurs only in a classroom. It is instead the basis of most (all?) human understanding, including scientific. As William James put it, in his 1890 Principles of Psychology: "What we experience, what comes before us, is a chaos of fragmentary impressions interrupting each other; what we think is an abstract system of hypothetical data and laws". The former are the experiences from which learning occurs, the latter the categories one uses to make sense of "reality". The issue is how one gets from one to the other, whether the categories are inherent in the experiences, and hence a reflection of the "real world", or are something else. James answer: "Every scientific conception is, in the first instance, a 'spontaneous variation' in someone's brain. For one that proves useful and applicable there are a thousand that perish through their worthlessness. Their genesis is striclty akin to that of the flashes of poetry and sallies of wit to which the instable brain-paths equally give rise. But whereas the poetry and wit (like the science of the ancients) are their own excuse for being ... the 'scientific' conceptions must prove their worth by being 'verified'. This test, however, is the cause of their preservation, not of their production ..." In short, the validity of science and related forms of advancing human understanding of external "reality" depend fundamentally not on the purity (or "objectivity") of their observations, but rather on the continual testing and retesting of generalizations which have, at their root, an origin in arbitrary categories.
Is there ONE kind of network, yet to be found, which could itself account for all kinds of learning? No one knows, of course. But some of the conclusions we've reached here may be relevant in thinking about the question. Learning is something which results simply from experience, but instead something that results from interactions between experience and pre-existing structure. It seems likely that different pre-existing structures (in terms of both network architecture and learning rules) would affect the ability to learn things (just as the pre-existing synaptic weights affect the categories created). If so, the bottom line may well be that there is no single, optimal learning network, and that "learning" itself will always need to be understood in terms of a series of different networks optimally structured for different tasks. And this, of course, presumes that one knows in advance all learning tasks. If learning itself generates new sorts of things to be learned, one can certainly confidently expect (and happily so, if one likes open horizons) that no single network will ever "solve" the learning problem.
Rosenblatt's Perceptron Learning Algorithm, a Java implementation which allows exploration of variations in learning parameters
Neural Nets, on line version of a book by Kevin Gurney, Psychology Department, University of Sheffield, United Kingdom
An Introduction to Neural Networks, by Leslie Smith, Centre for Cognitive and Computational Neuroscience, University of Stirling, United Kingdom
Neural Computing, course notes from Department of Electronics and Computer Science, University of Southampton, United Kingdom
Backpropagator's Review, by Don Tveter
Showcase, from Intelligent Financial Systems Ltd, includes examples of practical neural net use and some Java tutorials illustrating back-propagation networks.
FAQ for comp.ai.neural-nets newsgroup
Links related to neural networks and other simple interacting systems capable of learning are available from Artificial Life On Line
The first few chapter of James' Textbook of Psychology are available on line, together with the texts of several articles by him, at Classics in the History of Psychology, from York University, Canada
William James, an extensive web resource by Frank Pajares, Division of Educational Studies, Emory University
Mind and Body: Rene Descartes to William James", by Robert Wozniak, Department of Psychology, Bryn Mawr College
| Forum
| Complexity | Serendip Home |