
Albert S. Bregman Auditory Scene Analysis
Goal is to present a case study using Grobstein's "Bipartite Brain Model" as applied to linguistic sound structures1.0 Grobstein's Bipartite Brain Model
2.0 The modular organization of linguistic grammars
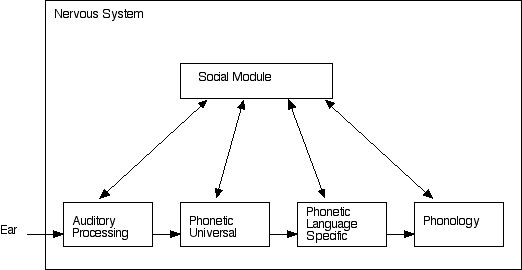
Roles of each of the modules:
Auditory Processing- biologically determined processing of auditory stimuli e.g. 'streaming' (Bregman 1990) of auditory stimuli, DECODER
Phonetic Universal- biologically determined processing that identifies 'language' and begins language specific processing, DECODER
Phonetic Language Specific- emergent module (guided by biologically determined biases) that encodes specific phonetic characteristics defined on a language by language basis MODEL BUILDER
Phonology- emergent module (guided by biologically determined biases) that encodes language specific symbolic sound patterns, MODEL BUILDER
Social Module- emergent module that encodes social aspects such as SEC, beauty/ugly, smart/stupid, race, gender, etc., STORY TELLER
Evidence for higher level modules:
Phonetic Language Specific: judgments on different dialects, L1 'foreign accents'
Phonology: different languages, L2 effects
'Information' becomes more abstract as higher level processing occurs:
Phonetic Universal- only phonetically relevant analyses, formants, transitions, etc.
Phonetic Language Specific- abstract phonetic categories
Phonology- distinctive features
Lower level 'information' is discarded at higher levels:
Phonetics Language Specific- accommodates 'intradialectical' variance (VOT, different formant values for vowels), acoustic differences e.g. 'high tone' for male may actually be lower in frequency than 'low tone' for female in a tone language (Mandarin)
Phonetics Universal- accommodates computer generated language vs. human language
The modules here fall into 'decoder', 'model builder' and 'story teller' depending on the following characteristics
-'model builder'- guided by biologically determined biases which produces flexible but constrained behavior
-'story teller' - input from multiple cross-modal modules, biologically guided (!?) to produce higher level patterns from distinct unrelated patterns
Work accomplished by each module is reduction of variability and enhancement of the stability of the pattern (analog to digital conversion)
CITI Bank Fraud Protection Commercials- the 'story teller at work'
-effect is only obtainable if we have 'patterns' of relationships between 'appearance' and 'language'
-if we separate the visual and auditory components of the commercial, there is no effect
(3) presents data from the Eastern Massachusetts dialect of English
| (3) illustrative pairings of Eastern Massachusetts English sentences (Halle and Idsardi 1997:332) | ||
|---|---|---|
| a. | the spa[r] is broken | the spar is broken |
| b. | the spa seems broken | the spa[ř] seems broken |
| c. | algebra[r] is difficult | Homer is difficult |
| d. | algebra bores me | Home[ř] bores me |
| e. | the study of algebra | the study of Home[ř] |
There is also an 'r-insertion' process active in this dialect which produces the homophones seen in (3)
/r/s remain in the memorized forms of words based on the lack of 'r-insertion' in certain contexts
| (4) underlying /r/ | |
|---|---|
| algebra ~ algebr[ej]-ic | *algebr[er]-ic |
| Homer ~ Hom[er]-ic | *Hom[ejř]-ic |
'r-insertion' only occurs in dialects of English that have 'r-dropping' and the question I want to focus on is why is this the case?
Halle and Idsardi (1997) provide formal analyses of 'r-insertion' and 'r-deletion' according to the rules in (4)
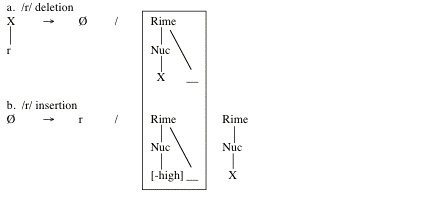
Halle and Idsardi draw attention to the important fact that the structural description of (4b) contains the structural description of (4a) which has important ramifications according to the 'Elsewhere Principle' (i.e. more specific instructions precede and block less specific instructions)
Halle and Idsardi further suggest that the origin of the 'r-insertion rule' is hypercorrection
Hypercorrection is a sociolinguistic term that refers to when an individual or group changes their behavior to model it after another group's linguistic behavior
'r-insertion' achieves the goal of 'more /r/s' which is socially desirable but the rule never-the-less still marks the hypercorrecting group as 'outsiders'
4.0 Why we need a 'story teller' for hypercorrection to work
Phonology itself is insufficient because one of its main tasks is to extrapolate away the particular type of information that is necessary
Phonology itself is impervious to 'social information', i.e. no phonological process is sensitive to:
All of the above distinctions are calculated at some level because of judgments people have about these social categories
The speaker who 'hypercorrects' must notice at least the following things
Specifically, for a speaker with an 'r-dropping' dialect:
The interaction between the 'story teller' and 'model builder' can be investigated by considering how the behavior is altered
Phonology as a module is 'fixed' at a point in time during the acquisition process where its rules and representations are impervious to change
The 'story teller' module can thus only manipulate the phonology in limited ways:
Both types of effects are seen in 'hypercorrection'
5.0 Caveats
All modules discussed here are drastically simplified- each module will have multiple representations and processes within them
Open question about other ways 'story tellers' can interact with 'model builders'-provided evidence about how the 'story teller' modifies phonology but what about other modules, 'vision'
References
Halle, Morris and William J. Idsardi (1997) r, hypercorrection and the Elsewhere Condition In Roca, Iggy (ed) Constraints and Derivations in Phonology. Oxford University Press.